# MQ
# 常见 MQ 模型
队列模型
最简单的消息模型,队列模式,用阻塞队列实现的生产者消费者模式,也可以看作一个队列模型的消息队列。

发布 - 订阅模型
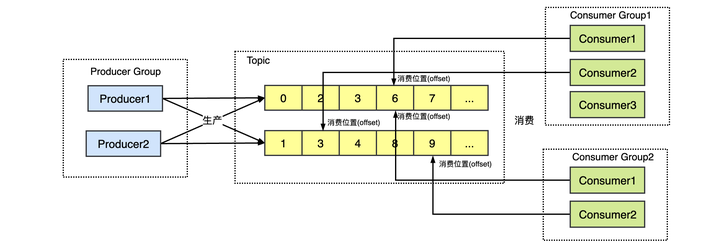
队列模式也可以有多个生产者消费者,但是同一个消息只能被一个消费者消费,为了解决这个为题,演化出了另一种消息模型 ** 发布 - 订阅模型(Publish-Subscribe Pattern)** 也被称为主题模型。

在发布 - 订阅模型中,消息的发送方称为发布者(Publisher),消息的接收方称为订阅者(Subscriber),服务端存放消息的容器称为主题(Topic)。发布者将消息发送到主题中,订阅者在接收消息之前需要先 “订阅主题”。每个订阅者都可以接收到主题的所有消息。
# Kafka
消息模型
服务架构
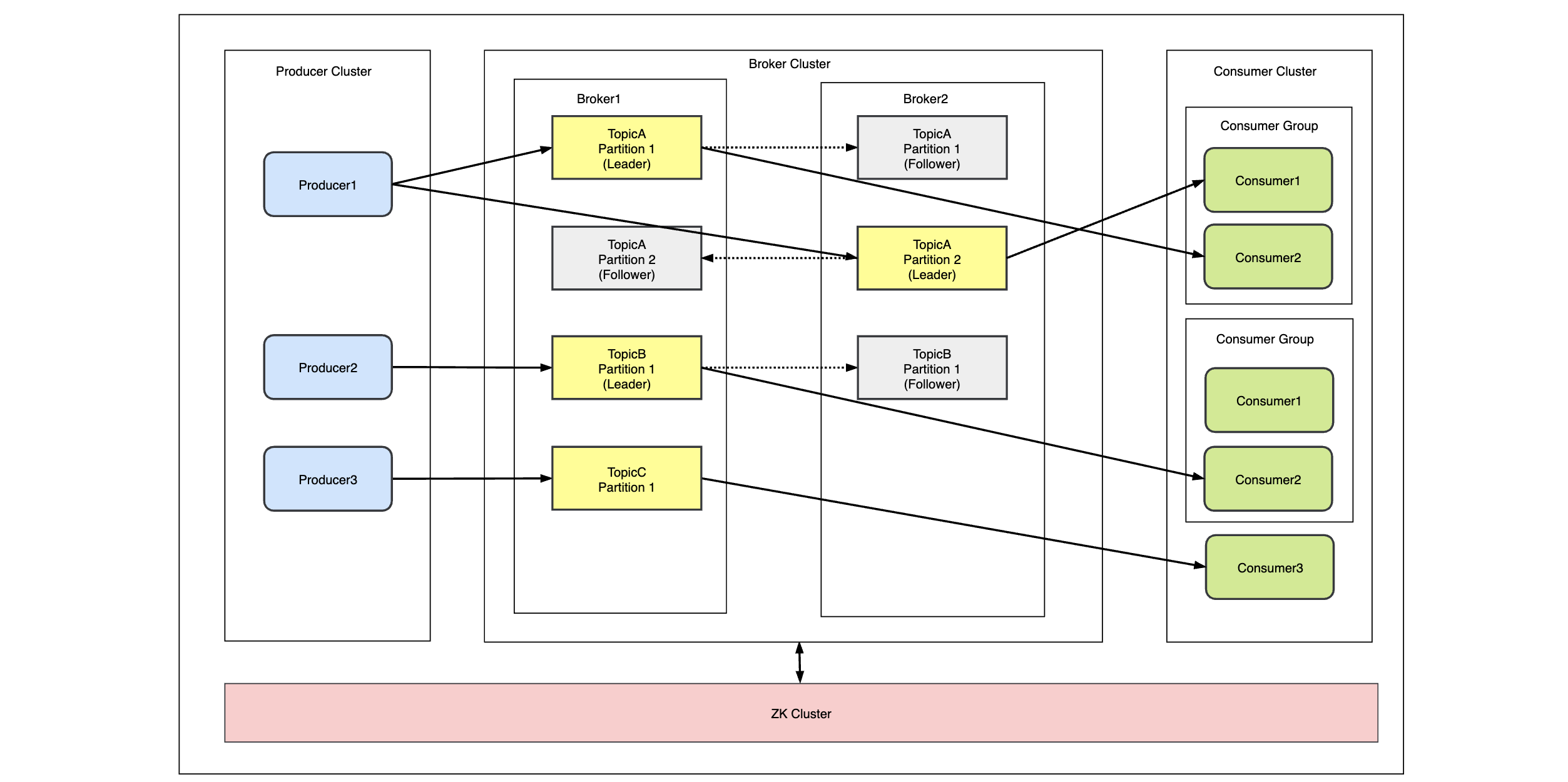
partition:kafka Topic 可以划分为多个 partition,分布在不同的 Broker 上,天然分布式,每个 patition 可以设置副本,其中主 partition 为 leader,副本 partition 为 follower,follower 和 leader 在不同的机器,消息的接收和发送都是 leader 负责的,follower partition 会从 leader 同步数据,如果 leader 所在的 borker 挂了,会从 follower 中选举一个成为 leader,高可用。
Consumer Group:在 kafka 的 Topic 的订阅单位也是 Consumer Group,每个消费组可以收到完整的消息,但是同一个分区的数据只能被消费者组中的某一个消费者消费,分区和消费者关系是多对一。
# MQ 的作用
- 解耦:将系统按照不同的业务功能拆分出来,消息生产者只管把消息发布到 MQ 中而不用管谁来取,消息消费者只管从 MQ 中取消息而不管是谁发布的。消息生产者和消费者都不知道对方的存在;
- 异步:主流程只需要完成业务的核心功能;对于业务非核心功能,将消息放入到消息队列之中进行异步处理,减少请求的等待,提高系统的总体性能;
- 削峰 / 限流:将所有请求都写到消息队列中,消费服务器按照自身能够处理的请求数从队列中拿到请求,防止请求并发过高将系统搞崩溃;
# MQ 的缺点
- 系统可用性降低:系统引用的外部依赖越多,越容易挂掉,如果 MQ 服务器挂掉,那么可能会导致整套系统崩溃。这时就要考虑如何保证消息队列的高可用了。
- 系统复杂度提高:加入消息队列之后,需要保证消息没有重复消费、如何处理消息丢失的情况、如何保证消息传递的有序性等问题。
- 数据一致性问题:A 系统处理完了直接返回成功了,使用者都以为你这个请求就成功了;但是问题是,要是 BCD 三个系统那里,BD 两个系统写库成功了,结果 C 系统写库失败了,就会导致数据不一致了。
# 常见 MQ 的对比
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 单机吞吐量 | 万级,比 RocketMQ、Kafka 低一个数量级 | 同 ActiveMQ | 10 万级,支撑高吞吐 | 10 万级,高吞吐,一般配合大数据类的系统来进行实时数据计算、日志采集等场景 |
| topic 数量对吞吐量的影响 | topic 可以达到几百 / 几千的级别,吞吐量会有较小幅度的下降,这是 RocketMQ 的一大优势,在同等机器下,可以支撑大量的 topic | topic 从几十到几百个时候,吞吐量会大幅度下降,在同等机器下,Kafka 尽量保证 topic 数量不要过多,如果要支撑大规模的 topic,需要增加更多的机器资源 | ||
| 时效性 | ms 级 | 微秒级,这是 RabbitMQ 的一大特点,延迟最低 | ms 级 | 延迟在 ms 级以内 |
| 可用性 | 高,基于主从架构实现高可用 | 同 ActiveMQ | 非常高,分布式架构 | 非常高,分布式,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
| 消息可靠性 | 有较低的概率丢失数据 | 基本不丢 | 经过参数优化配置,可以做到 0 丢失 | 同 RocketMQ |
| 功能支持 | MQ 领域的功能极其完备 | 基于 erlang 开发,并发能力很强,性能极好,延时很低 | MQ 功能较为完善,还是分布式的,扩展性好 | 功能较为简单,主要支持简单的 MQ 功能,在大数据领域的实时计算以及日志采集被大规模使用 |
# 如何保证消息不被重复消费
因为消息队列的服务质量是 At least once ,因此消息队列无法保证消息不重复,因此消费重复的问题得由 Consumer 端来解决。
一般采用幂等性解决重复消息问题。所以「如何保证消息不被重复消费?」就转变为「如何保证消费者的幂等性?」
那么如何保证幂等性呢?
- 写数据时,先根据主键查一下这条数据是否存在,如果已经存在则 update;
- 数据库的唯一键约束也可以保证不会重复插入多条,因为重复插入多条只会报错,不会导致数据库中出现脏数据;
- 如果是写 redis,就没有问题,因为 set 操作是天然幂等性的。
# 如何保证消息不丢失,进行可靠性传输
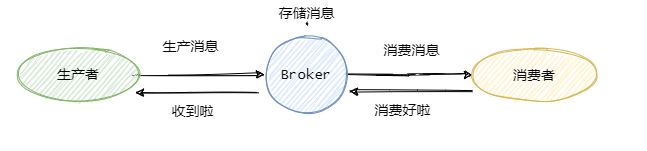
可以看到一共有三个阶段,分别是生产消息、存储消息和消费消息。我们从这三个阶段分别入手来看看如何确保消息不会丢失。
生产消息
生产者发送消息至 Broker,需要处理 Broker 的响应,不论是同步还是异步发送消息,同步和异步回调都需要做好 try-catch,妥善的处理响应,如果 Broker 返回写入失败等错误消息,需要重试发送。当多次发送失败需要作报警,日志记录等。
这样就能保证在生产消息阶段消息不会丢失。
存储消息
存储消息阶段需要在消息刷盘之后再给生产者响应,假设消息写入缓存中就返回响应,那么机器突然断电这消息就没了,而生产者以为已经发送成功了。
如果 Broker 是集群部署,有多副本机制,即消息不仅仅要写入当前 Broker, 还需要写入副本机中。那配置成至少写入两台机子后再给生产者响应。这样基本上就能保证存储的可靠了。
消费消息
这里经常会有同学犯错,有些同学当消费者拿到消息之后直接存入内存队列中就直接返回给 Broker 消费成功,这是不对的。
你需要考虑拿到消息放在内存之后消费者就宕机了怎么办。所以我们应该在消费者真正执行完业务逻辑之后,再发送给 Broker 消费成功,这才是真正的消费了。
所以只要我们在消息业务逻辑处理完成之后再给 Broker 响应,那么消费阶段消息就不会丢失。
小结一下
可以看出,保证消息的可靠性需要三方配合。
- 生产者需要处理好 Broker 的响应,出错情况下利用重试、报警等手段。
- Broker 需要控制响应的时机,单机情况下是消息刷盘后返回响应,集群多副本情况下,即发送至两个副本及以上的情况下再返回响应。
- 消费者需要在执行完真正的业务逻辑之后再返回响应给 Broker。
# 如何保证消息的有序性
有序性分:全局有序和部分有序。
全局有序
如果要保证消息的全局有序,首先只能由一个生产者往 Topic 发送消息,并且一个 Topic 内部只能有一个队列(分区)。消费者也必须是单线程消费这个队列。这样的消息就是全局有序的!
不过一般情况下我们都不需要全局有序,即使是同步 MySQL Binlog 也只需要保证单表消息有序即可。

部分有序
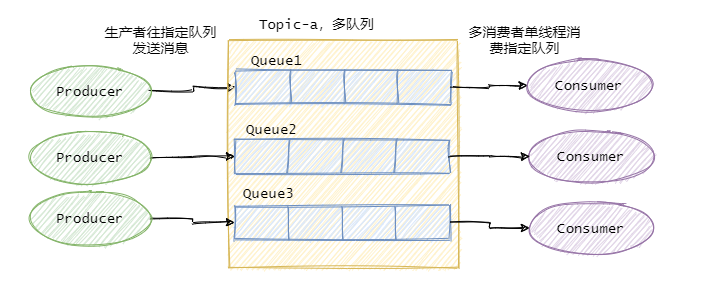
因此绝大部分的有序需求是部分有序,部分有序我们就可以将 Topic 内部划分成我们需要的队列数,把消息通过特定的策略发往固定的队列中,然后每个队列对应一个单线程处理的消费者。这样即完成了部分有序的需求,又可以通过队列数量的并发来提高消息处理效率。
# 如何处理消息堆积情况
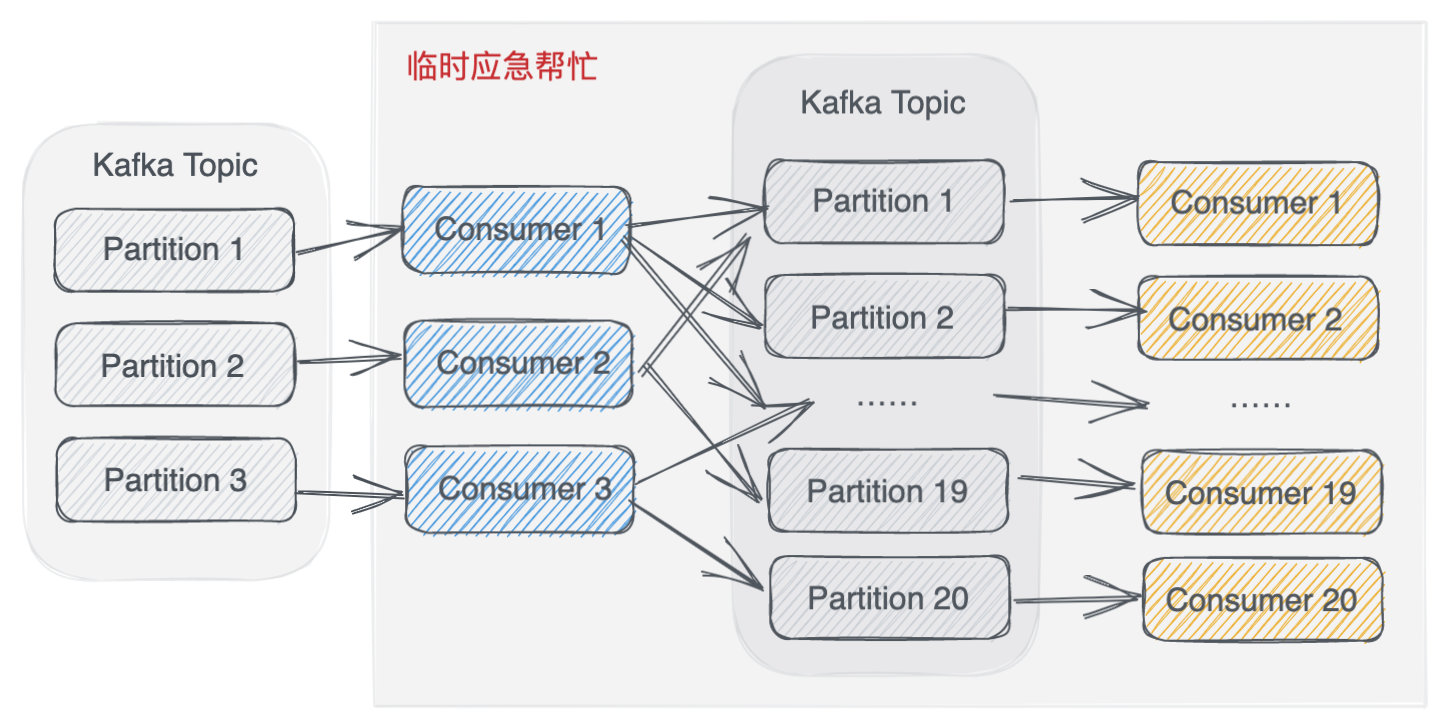
新建一个临时的 Topic,设置为 5*X 个 Partition。
原 Consumer 不再处理业务逻辑了,只负责搬运,把消息放到临时 Topic 中。
这 5*X 个 Partition 可以有 5*X 个 Consumer 了,它们来处理原来的业务逻辑。
这 5*X 个 Consumer 每秒一共能处理原来五倍数量的消息了,这样就可以快速处理完积压的消息。
当处理完消息积压后,将原来的 Topic 分区增加到适当数量,把整体结构恢复为原来的形式。